CI/CD Git: CI フレンドリーな Git リポジトリに役立つ 5 つのヒント
成功に向けて準備を整えましょう、すべてはリポジトリから始まります。

Sarah Goff-Dupont
主筆
Git と継続的なデリバリーはソフトウェアの世界で時折出会う「チョコレートとピーナッツ バター」のような組み合わせです。つまり、美味しいもの同士を組み合わせると一層美味しくなるということです。そこで、Bamboo 内のビルドと Bitbucket リポジトリをうまく組み合わせるヒントを共有します。ほとんどのインタラクションは継続的なデリバリーのビルドまたはテスト フェーズで発生するため、この記事では「CD (継続的なデリバリー)」よりも「CI (継続的なインテグレーション)」の見地から説明します。
1: 大きなファイルはリポジトリの外に保存する
Git についてよく耳にする話の 1 つですが、バイナリファイルやメディアファイル、アーカイブされたアーティファクトなど、大規模なファイルをリポジトリに置くのは避けるべきだと言われています。いったんファイルを追加すると、そのファイルは常にリポジトリの履歴に含まれ、レポジトリが複製されるたびに、巨大な重いファイルが一緒にクローンされることになります。
リポジトリの履歴からファイルを取り出すのは注意が必要な作業で、いわばコード ベース上で前頭葉を切断する手術をするようなものです。こうした外科手術的なファイル抽出によってリポジトリの履歴がすべて変更されて、どんな変更がいつ行われたか明確に把握することができなくなります。こうした理由から、原則として容量の大きいファイルはリポジトリに置かないようにします。さらに...
Git リポジトリから大きなファイルを排除することは、CI にとって特に重要です。
ビルドするたびに、CI サーバーはリポジトリのクローンを作業ビルド ディレクトリに作成しなければなりません。リポジトリが山とある巨大なアーティファクトで膨れあがっている場合、その処理が遅くなり、開発者がビルド結果を待っていなければならない時間が長くなります。
それはいいとしましょう。しかし、もしビルドが他のプロジェクトや大規模なアーティファクトのバイナリに依存している場合はどうでしょうか? これは非常によくある状況であり、おそらくこれからも変わることはないと思われます。では質問です。どのようにすればこれを効果的に処理できるでしょうか。
ソリューションを見る
Open DevOps によるソフトウェアの構築と運用
関連資料
トランク ベース開発の詳細
Artifactory (Bamboo 用のアドオンを作成)、Nexus、Archiva のような外部ストレージ システムには、自分のチームや周囲のチームが生成するアーティファクトに対するサポート機能があります。こうしたシステムでは、ビルド開始時に必要なファイルをビルド ディレクトリにプルできます。Maven や Gradle を通してサード パーティのライブラリをプルするようなものです。
プロからのヒント: アーティファクトが頻繁に変更する場合は、毎晩大きなファイルをビルド サーバーに同期せずに、ビルド時にディスク全体に転送するようにしましょう。夜間同期の合間は、結局、古いバージョンのアーティファクトでビルドすることになりますし、開発者はビルド時にこれらのファイルがローカル ワークステーションに必要です。したがって、総合的に考えて、ビルド時にアーティファクトをダウンロードするのが最もクリーンな方法です。
ネットワーク上に外部ストレージ システムがまだない場合は、Git Large File 対応 (LFS) の活用が最も簡単です。
Git LFS はリポジトリの大きなファイルにファイルそのものではなくポインターを保存する拡張機能です。ファイル自体はリモートサーバーに保存されます。ご想像のとおり、これでクローン時間が大幅に短縮されます。
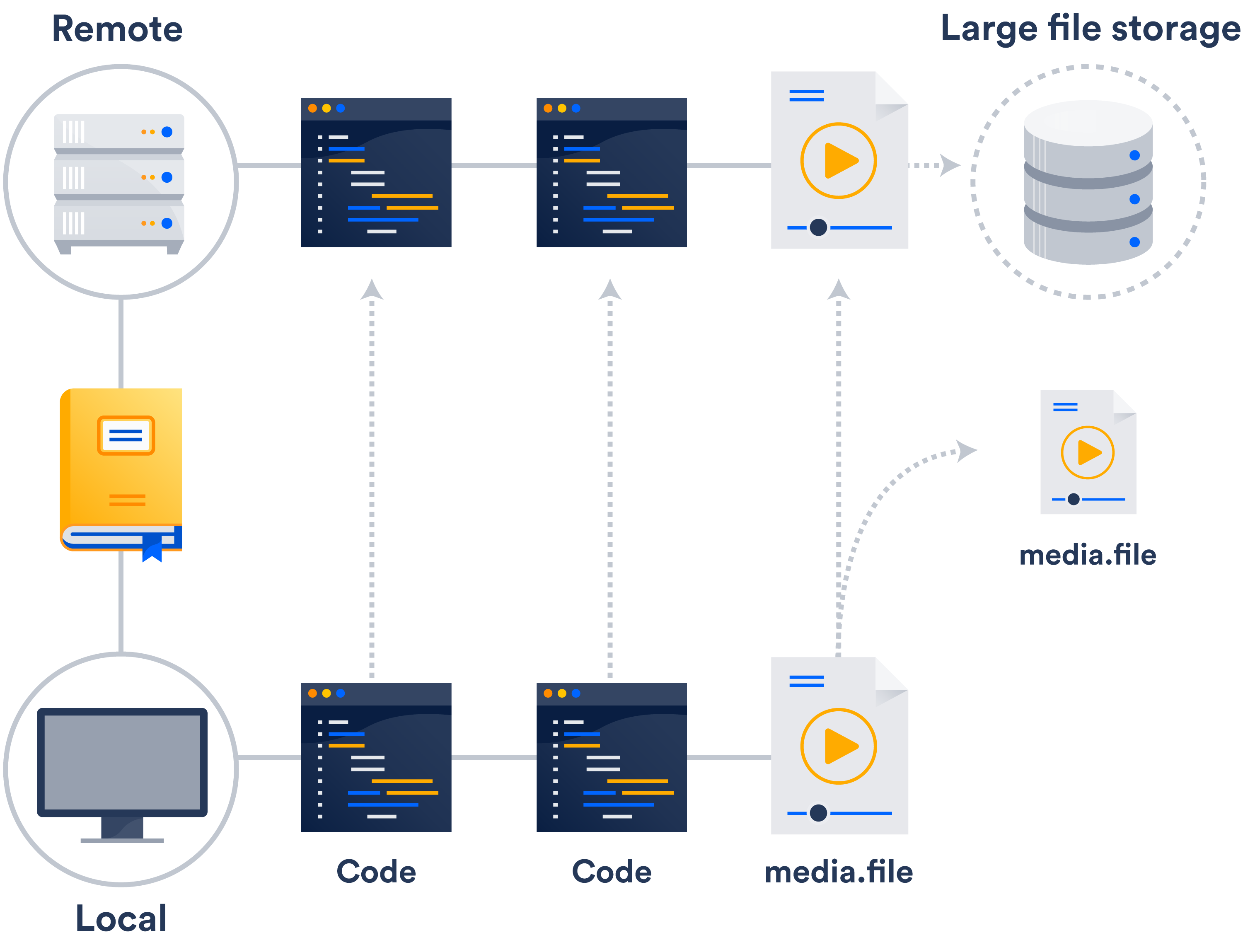
おそらく、Git LFS はすでに利用できます。Bitbucket と GitHub はどちらも Git LFS 対応です。
2: CI の shallow clone を使用する
ビルドを実行するたびに、ビルド サーバーはリポジトリのクローンを現在の作業ディレクトリに作成します。以前述べたとおり、リポジトリのクローンを作成する際、Git は既定でリポジトリ全体の履歴のクローンを作成します。そのため、この操作は時が経つにつれますます時間がかかるようになります。
シャロー クローンを使えば、リポジトリの現在のスナップショットだけがプルされます。そのため、特に大規模な古いリポジトリで作業をする場合、この方法はビルドの時間を削減する非常に有効な手段となります。
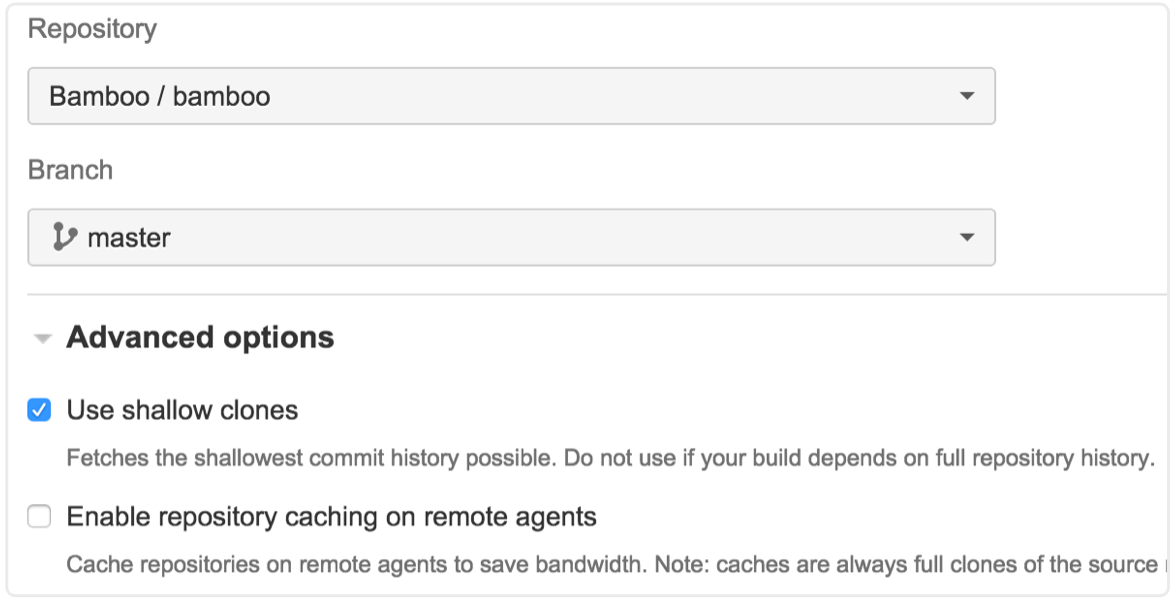
しかし、ビルドが完全なリポジトリの履歴を必要とする場合はどうでしょう。たとえば、ビルド内の工程で POM (または類似の) のバージョン番号を更新する場合、または 2 つのブランチを各ビルドにマージする場合などです。どちらのケースでもリポジトリに変更を反映するには Bamboo が必要になります。
Git では、ファイルの簡単な変更 (バージョン番号の更新など) は、履歴全体がなくてもプッシュできます。しかし、マージについては、Git が 2 つのブランチをさかのぼって共通の祖先を見つける必要があるため、依然としてリポジトリの履歴が必要です。ビルドでシャロー クローンを利用している場合は、このことが問題になります。そこで 3 つめのヒントが登場します。
3: ビルドエージェントでリポジトリをキャッシュする
これによって、クローン作成操作が大幅に高速化します。Bamboo では初期設定でこれが実行されます。
リポジトリキャッシングが役に立つのは、複数のビルドを通じてエージェントを使用している場合のみです。EC2 や他のクラウドプロバイダーでビルドを実行するたびに、ビルドエージェントを作成し削除している場合は、リポジトリキャッシングに意味がなくなります。なぜなら、空のビルドディレクトリで作業していることになり、どのみち毎回リポジトリのフルコピーをプルする必要があるためです。
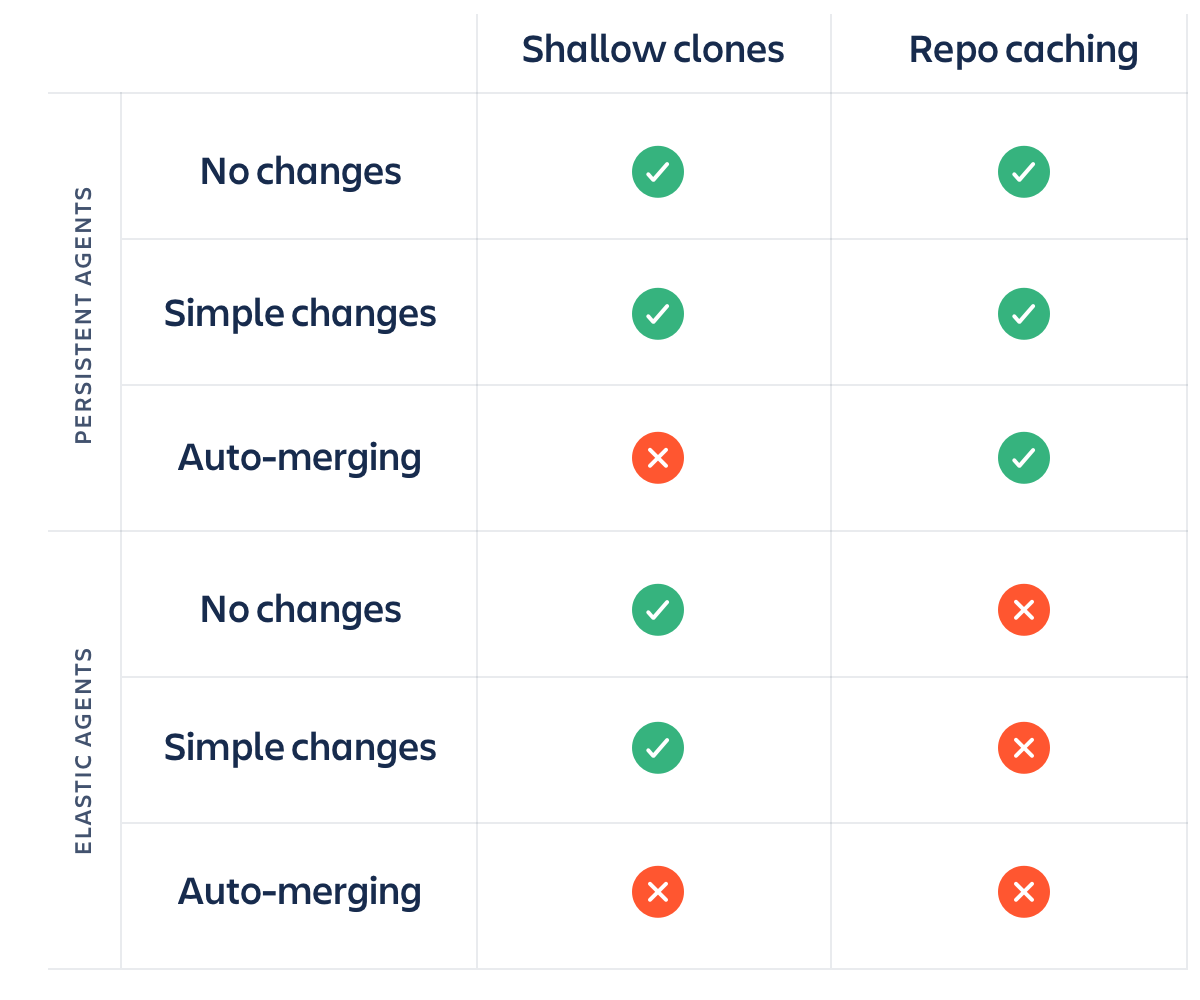
Shallow clone とリポジトリキャッシングを足して常住エージェントまたはエラスティックエージェントを割ると興味深い事実が分かります。以下の表は戦略を立てる際に役立ちます。
4: トリガーを上手に選ぶ
アクティブなブランチのすべてで CI を実行することがよいのは(ほぼ)言うまでもないことです。しかし、あらゆるコミットに対してすべてのブランチでビルドを実行するのはよい考えと言えるでしょうか。たぶん変わりません。その理由は次のとおりです。
たとえば、アトラシアンの場合を考えてみましょう。アトラシアンには 800 人を超える開発者がいて、それぞれ毎日数回リポジトリに変更をプッシュしています。そのほとんどはフィーチャー ブランチへのプッシュです。ビルドの回数は大量です。ビルド エージェントの数をただちに大きく増やさない限り、大量の待ち行列ができます。
アトラシアンの内部 Bamboo サーバーの 1 つには、さまざまなビルド プランが 935 本収納されています。アトラシアンでは 141 のビルド エージェントをこのサーバーに接続して、アーティファクト パッシングやテストの並行実施といったベスト プラクティスによって各ビルドを可能な限り効率的に行えるようにしました。それでもなお、プッシュのたびにビルドすると作業が停滞しました。
Bamboo インスタンスごとに 100 以上のエージェントを毎回ひたすら設定するかわりに、一歩下がってこの作業は本当に必要か考えてみました。答えはノーでした。
そこで、ブランチビルドを常に自動的にトリガーするのではなく、開発者にプッシュボタンを作成する選択肢を与えました。これは厳密なテストとリソースの保全のバランスを取るよい方法です。ほとんどの変更アクティビティはブランチで発生していることから、大きく節約できるチャンスがあります。
開発者の多くはプッシュボタンによる追加制御を好み、ワークフローに自然になじむと感じています。いつビルドを実行するか考えずにすむ自動トリガーを好む開発者もいます。どちらのアプローチも有効です。重要な点は、まずブランチをテストし、ビルドに問題がないことを確認してから上流にマージすることです。

ただし、main や安定版リリース ブランチのような重要なブランチでは話は別です。これらのブランチにおけるビルドは、リポジトリの変更をポーリングするか、Bitbucket から Bamboo にプッシュ通知を送信することによって自動でトリガーされます。すべての進行中の作業で開発ブランチを使用しているため、main に入るコミットは (理論的には) マージされる開発ブランチのみのはずです。さらに、これらのコード行はリリースや開発ブランチ作成の元になります。したがって、各マージに対してタイムリーなテスト結果を得ることが非常に重要です。
5: ポーリングを止めて、フックを始める
数分おきにリポジトリをポーリングして変更を探すのは、Bamboo にとって非常に容易な操作です。しかし、数千のブランチに対する数百のビルドになり、数十個のリポジトリが関与するとなると、あっという間に負荷が膨れ上がります。Bamboo をポーリングする代わりに、変更がプッシュされてビルドが必要になったときに Bitbucket で合図するように設定できます。
通常、この作業はリポジトリにフックを追加することで行いますが、折よく行われた Bitbucket と Bamboo の統合によってこうした内部のセットアップがすべて行われます。Bamboo と Bitbucket をバック エンドでリンクすれば、リポジトリ主導のビルド トリガーが細かい設定なしで即時に機能します。フックも特別な設定も不要です。
ツールに関係なく、リポジトリ主導のトリガーには、ターゲット ブランチがアクティブでなくなったときに自動で終了するというメリットがあります。つまり、何百もの放棄されたブランチをポーリングして CI システムの CPU サイクルを無駄にすることはありません。または、ブランチのビルドを手動でオフにする作業でユーザーが時間を無駄にすることもありません (ただし、やはりポーリングが必要であれば、アクティブでない期間が X 日間続いた後にブランチを無視するように Bamboo を簡単に設定できることは注目に値します)。
CI で Git を使用する鍵は...

この記事を共有する
次のトピック
おすすめコンテンツ
次のリソースをブックマークして、DevOps チームのタイプに関する詳細や、アトラシアンの DevOps についての継続的な更新をご覧ください。

DevOps コミュニティ

ブログを読む